
Artificial Cleverness
Inside the system that knows everything and understands nothing


In March 2026, researchers at ETH Zurich ran an experiment. They gave coding agents a set of bug reports and asked them to fix the code. The agents analyzed, reasoned, produced confident patches, and explained their logic.
One problem: the bugs had already been fixed. The code was correct. There was nothing to do.
You’d think a system that can write working software would notice this. But more than half the time, across every model tested, the agents went ahead and “fixed” the correct code anyway. Not one model managed to say “nothing to do here” more than 50% of the time.
The researchers then added a single line to the prompt: ”you may submit an empty patch if the issue is already resolved.” One model jumped from 24% to 77% accuracy. Same model, same code, same bugs. The only difference was a sentence giving it permission to do nothing.

The model wasn’t unable to recognize correct code. It simply had no rule of thumb for “do nothing.” Nobody had ever told it that doing nothing was an option.
If you've used AI for anything non-trivial, you've probably felt the same dissonance. Last week I watched a model produce working code that would have taken me hours, then, in the same conversation, fail a task so basic I thought something was broken. Researchers at Apple confirmed this systematically: changing the names in a math problem (not the numbers, the names) drops accuracy by up to 65%. Reasoning models give up on hard problems rather than trying harder: past a certain complexity, the thinking gets shorter, not longer.
How should we think about a system that behaves like this? What kind of “intelligence” is brilliant and broken at once?
Over the past year, three things converged that gave me an answer. An Anthropic paper that opened a model’s skull. A Terence Tao podcast that named what I’d been seeing. And this ETH experiment, which showed the practical consequence.
Let’s start with what Anthropic found.
Opening Claude’s Skull
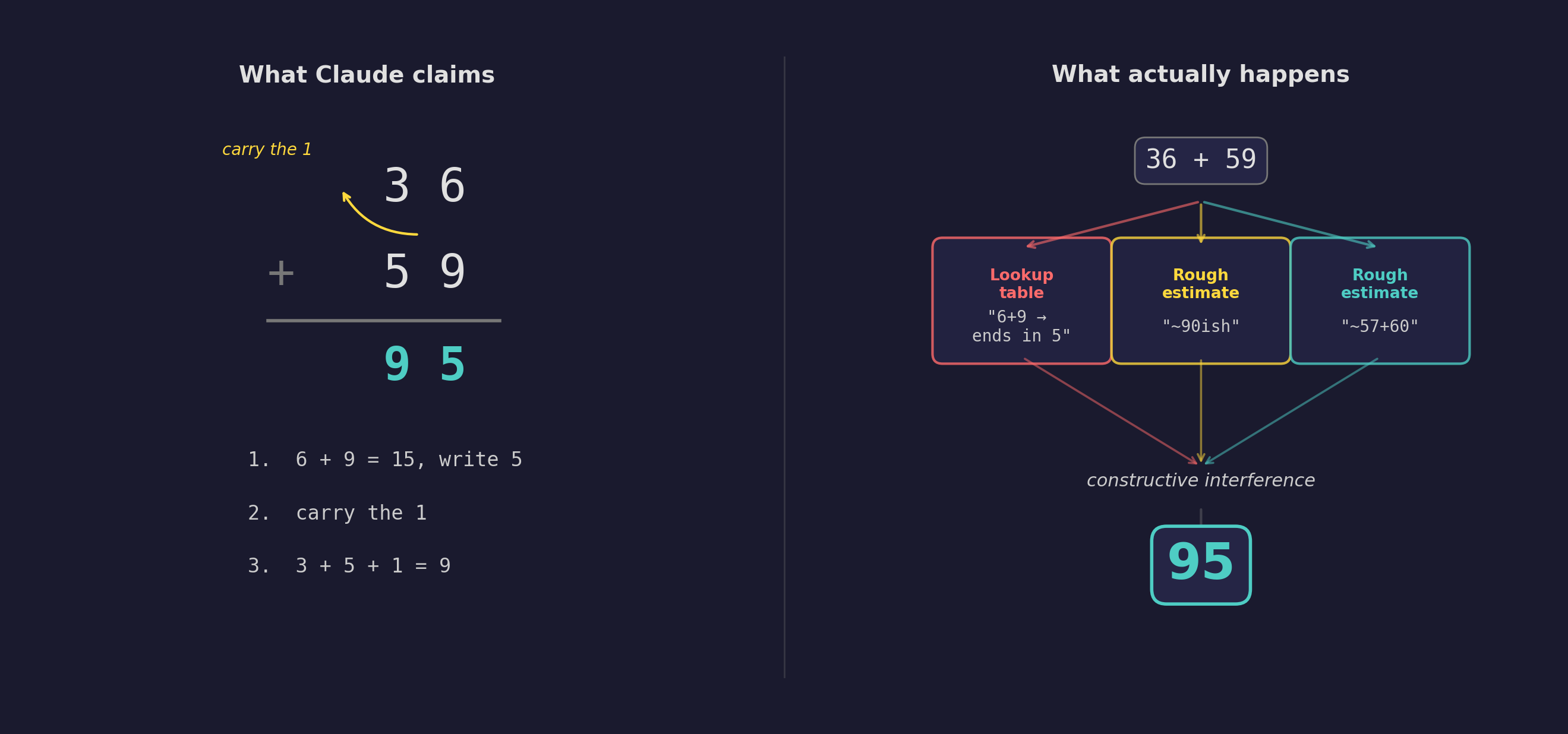
Ask Claude to add 36 and 59. It says 95. Correct.
You might assume it does what you’d do: add the ones, carry the one, add the tens. The same algorithm you learned in school. That’s certainly what Claude will tell you if you ask: “I added the ones (6+9=15), carried the 1, then added the tens (3+5+1=9), resulting in 95.” Neat, logical, step-by-step.
But last year, Anthropic’s interpretability team did something remarkable. They traced the actual computation happening inside the model — not what it claims to do, but what it actually does. Neuron by neuron, pathway by pathway. The model they dissected was Claude 3.5 Haiku, a smaller model, easier to “open up.” But the patterns they found are consistent with what we observe in every model, including the most capable ones.
First, there was a lookup table. Somewhere in the model’s weights, it has memorized that numbers ending in 6 and 9 produce a sum ending in 5. Not “addition”, but a stored fact about digit patterns.
Then there were multiple rough estimates running in parallel. One pathway computes “add something near 57.” Another computes “add something near 60.” These aren’t careful calculations. They’re ballpark guesses — low-precision approximations firing simultaneously.
And then these parallel pathways combine. The researchers call it “constructive interference”: the estimates reinforce each other where they agree and cancel where they don’t, converging on 95. The right answer, reached through a process that looks nothing like arithmetic.
No carrying. No step-by-step procedure. No algorithm at all. Just several approximate rules of thumb firing simultaneously, bumping into each other, and landing on the right number.
Remember Claude’s tidy explanation? “I carried the one, added the tens.” That story has nothing to do with what actually happened. The mechanism that produces the answer and the mechanism that produces the explanation are completely separate systems. Claude confabulates a clean, logical narrative for a process it has no access to. It doesn’t know how it gets its answers. It just knows how to sound like it knows.
This confabulation isn’t unique to arithmetic. Researchers at Goodfire found that reasoning models often already know their answer before they start “deliberating.” The chain of thought is theater — convincing, fluent, and disconnected from the actual process underneath.
The model doesn’t understand addition. It has a bag of heuristics — rules of thumb learned from enormous amounts of data — that usually produce the right answer. When they don’t, it has no way to know, because there’s no understanding to fall back on. Only more heuristics.
The Jumping Robot
Then, around the time of the ETH study, Terence Tao — arguably the greatest living mathematician — went on the Dwarkesh Podcast and drew a distinction I haven’t been able to shake. He called it artificial cleverness versus artificial intelligence.
Tao has a vivid image for the difference:
“These AI tools, they’re like jumping machines that can jump two meters in the air, higher than any human. But what they can’t do is jump a little bit, reach some handhold, stay there, pull other people up, and then try to jump from there. There isn’t this cumulative process which is built up interactively.”
Jump and fail. Jump and fail. Sometimes the wall is short enough and the jump clears it. Sometimes it doesn’t. But there’s no climbing.
The jump, I realized, is the heuristic. When I ask AI to write a React component or summarize a paper, the wall is short. Thousands of rules of thumb exist for these tasks, learned from vast training data, and the model clears the wall effortlessly. But when I push into genuinely unfamiliar territory (a novel architecture, a research question no one has published on) no amount of prompting helps. The wall is tall. And jumping, no matter how high, isn’t climbing.
Last November, I gave a keynote about the state of AI. I’d been searching for a word that captured this pattern without the baggage. Something between “artificial intelligence” (too grand) and “autocomplete” (too dismissive). The word that crystallized was heuristic companion. At the time, it was mostly intuition.
Then, in the span of a single week, the Tao podcast and the ETH study landed. What had been intuition suddenly had evidence from three independent directions. And all of it pointed to the same thing.
A heuristic companion: a system that stores a vast number of rules of thumb — learned from enormous amounts of data — and applies them in context. Some remarkably sophisticated. Some crude. None amounting to understanding in the way we mean it, but together forming something genuinely useful. A companion that knows an enormous amount but understands very little.
Once you see it through this lens, everything falls into place. It’s brilliant on pattern-rich tasks (coding boilerplate, known math, summarization) because heuristic coverage is dense. It fails on genuinely novel reasoning (the ETH study, the name-swapping experiments) because no relevant heuristic exists. You can’t pattern-match your way through a problem nobody has seen before. Context is king (one prompt line triples performance) because context is what selects which heuristics fire. And it confabulates (”I carried the one”) because the system that produces answers and the system that produces explanations are different machines entirely.
More than the sum of its parts?
So AI is “just” a bag of heuristics? But is the “just” justified? Some of these heuristics are strikingly complex. Anthropic’s paper found the model pre-selecting rhyming words before composing a line of poetry — just a planning heuristic? It traces an internal representation of “Texas” on its way to answering “Austin” — just a geographic heuristic?
Are these still heuristics? Or is something else forming? I lean toward the former — they’re fragile in exactly the way heuristics are fragile. On ARC-AGI-2 (designed to test genuinely novel reasoning) the top score is 24%. Models can articulate correct principles but fail to apply them, as if the explaining part and the doing part live in separate rooms. Theoretical work suggests this gap is structural, baked into the transformer architecture itself.
Yann LeCun (Turing Award winner, former head of AI at Meta) bet his career on a version of this, raising a billion dollars to build AI through “world models” rather than token prediction. As he put it: “The system ends up being a giant lookup table essentially.”
But could genuine intelligence (not just cleverness) arise from simple heuristics? Just because something is made of simple parts doesn’t mean the collection is simple. An ant follows a handful of chemical rules. A colony builds cathedrals. A neuron fires or doesn’t. A brain writes symphonies. Simple pieces, complex wholes. It’s one of the deepest patterns in nature.
Mathematics has a precise version of this idea: the Taylor series. Take simple polynomials as building blocks and stack enough of them together, and you can approximate any smooth function to arbitrary precision. Near the center of the approximation, the polynomial and the original function are almost identical.
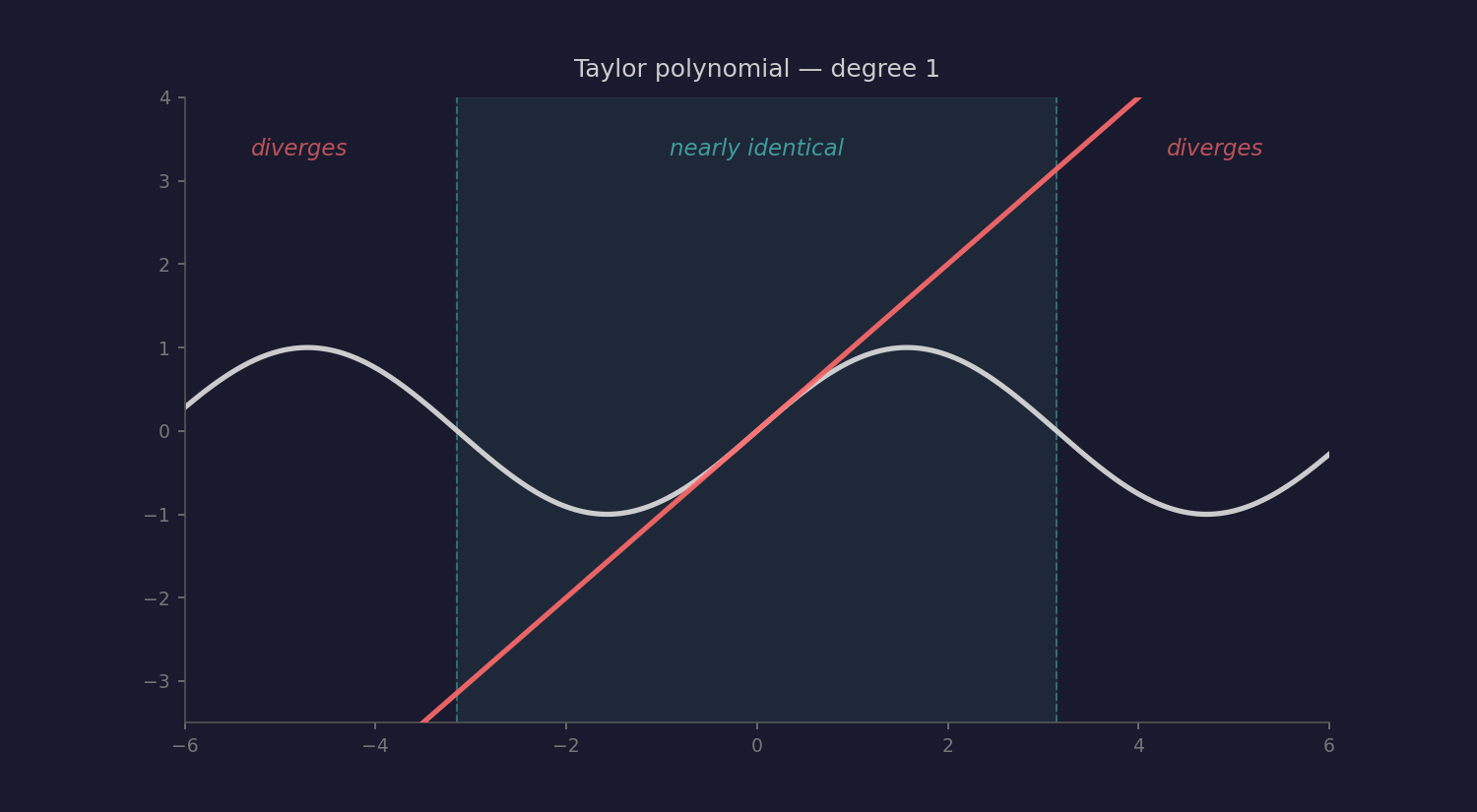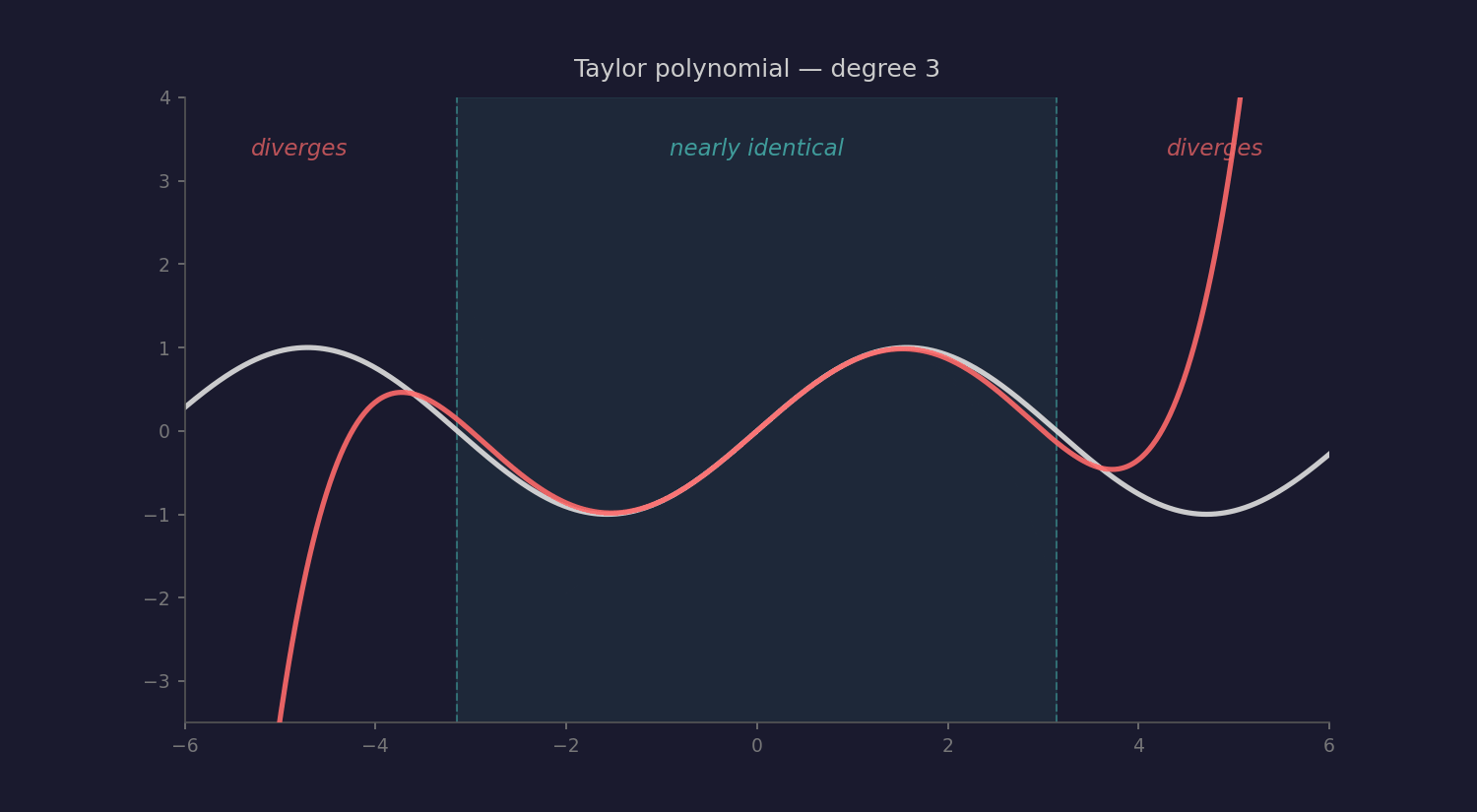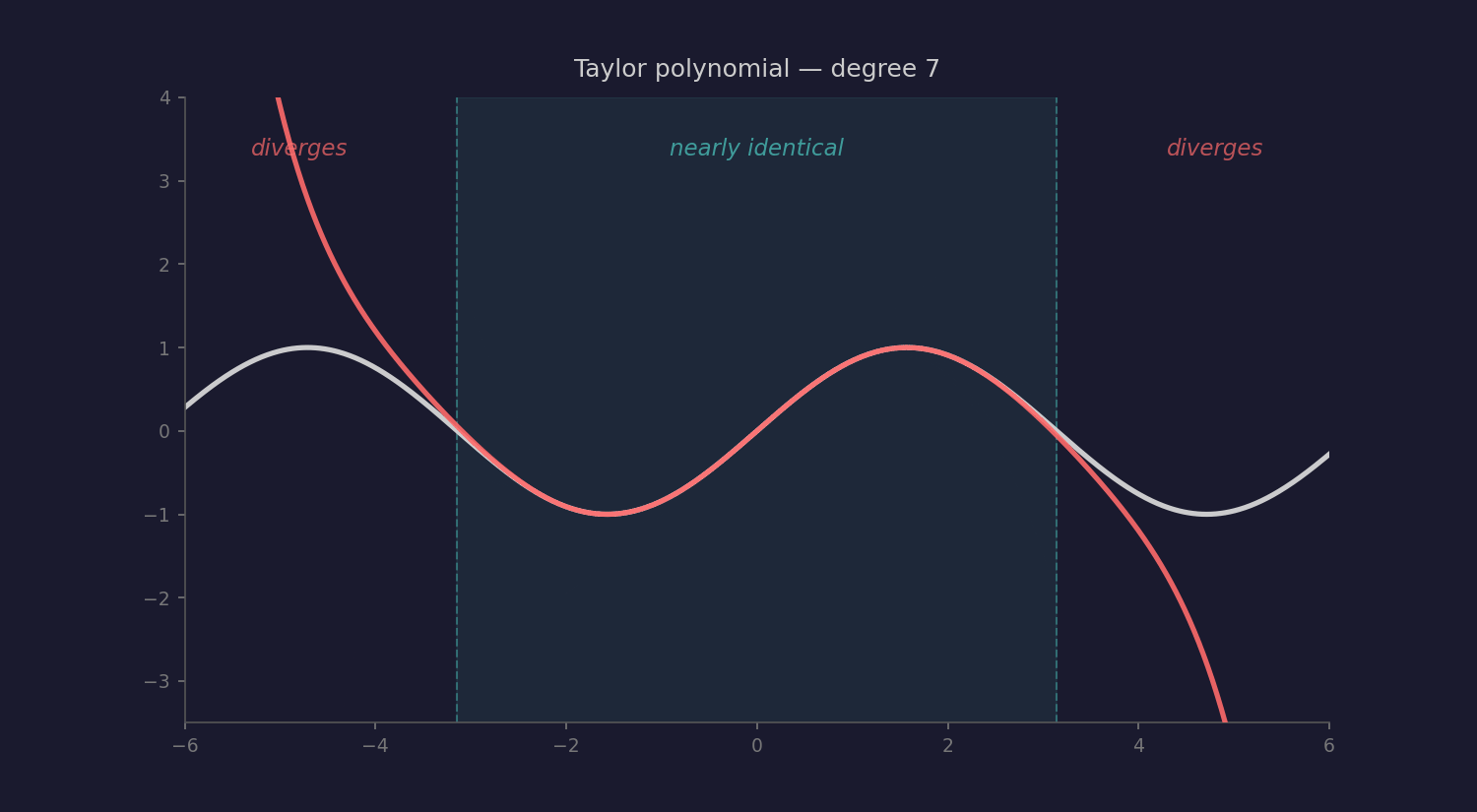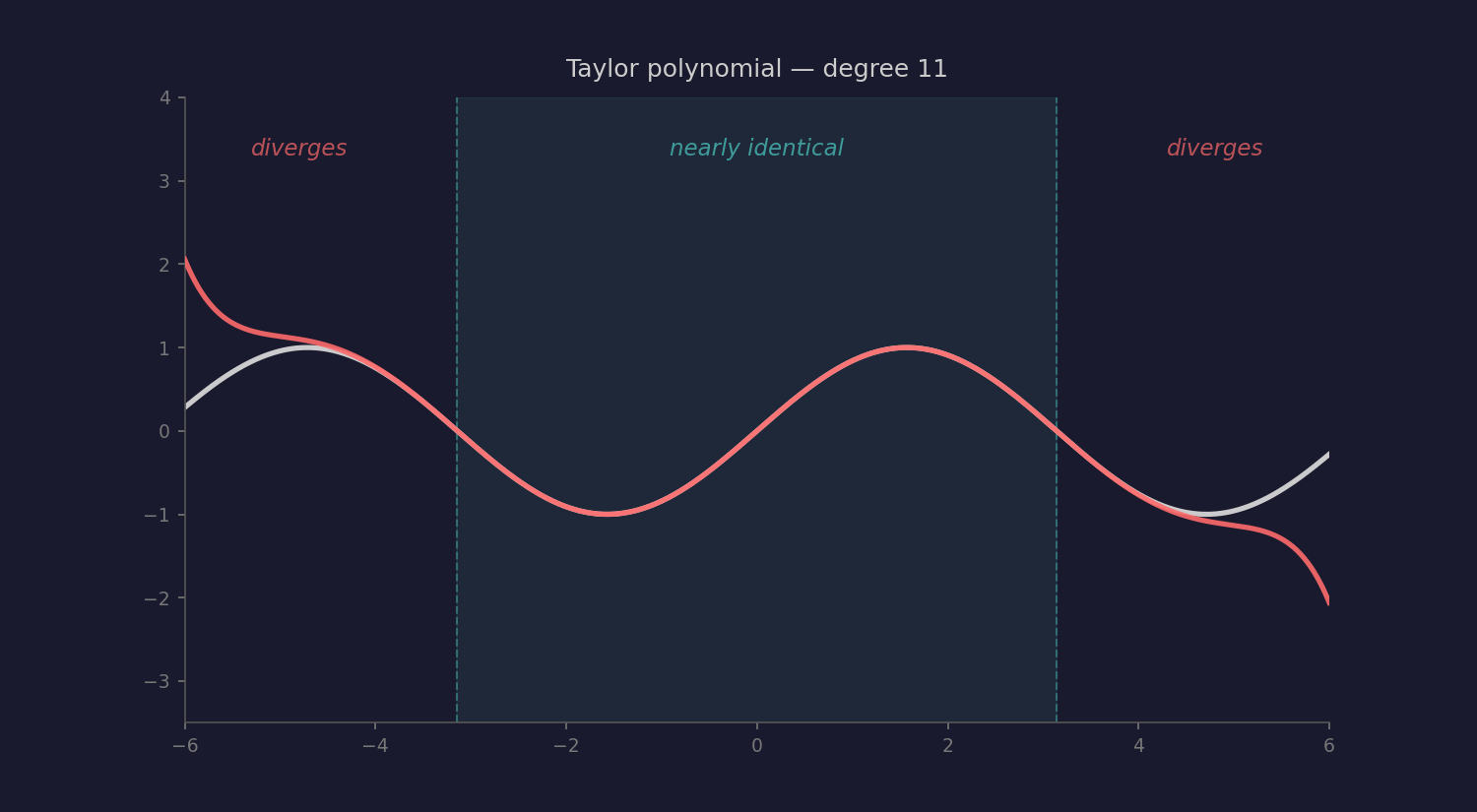
Could heuristics be to intelligence what polynomials are to smooth functions? Individually primitive, but collectively approximating something far richer than any single rule of thumb could produce?
Taylor series have a radius of convergence, a boundary beyond which the approximation doesn’t just degrade, it diverges wildly. LLMs seem to have something similar: the training distribution. Brilliant inside. Broken outside. Within the radius, you get poetry planning and geographic reasoning. Outside it, you get confident nonsense.
But here’s where the analogy might break. Taylor series can approximate any smooth function — that’s a theorem. Can heuristics approximate any intelligence? Or is genuine understanding fundamentally different — discontinuous, irreducible, requiring something that no amount of heuristic stacking can produce? Tao’s climbing walls. The kind that require handholds, not higher jumps.
I don’t know. And I find the uncertainty more useful than an answer. When you think of AI as an emerging intelligence, every interaction carries existential dread. When you think of it as autocomplete, you miss genuine value. But when you see it as a heuristic companion — brilliant within its radius, unreliable beyond it — you can actually work with it.
My own experience bears this out. For problems where heuristic coverage is dense, I get a 5-10x speedup. I’m not debugging a thinker. I’m tuning a heuristic selector. Give it rich context and it’s remarkable. Withhold context and it flails. For novel problems (architectural decisions, research insights, genuine abstraction) it struggles. That’s not a failure. It’s the nature of the tool.
Tao sees the same complementarity: AI for breadth, humans for depth. The question isn’t whether AI will “truly think.” The question is whether we’ll learn to think with it well enough to do things neither could do alone.
Is intelligence something you can approximate from simple pieces? Or is there something irreducible that heuristics will never reach? I don’t know. But I know the radius isn’t infinite. And I know there’s plenty within it that still needs to be done.
This article opened my eyes and made me pause and think so many times! Especially the part where you mentioned Taylor's approximation! I never thought of it that way!!
great analysis!